(Collaborative post by Mateusz “j00ru” Jurczyk and Gynvael Coldwind)
It was six weeks ago when we first introduced our effort to locate and eliminate the so-called double fetch (e.g. time-of-check-to-time-of-use during user-land memory access) vulnerabilities in operating system kernels through CPU-level operating system instrumentation, a project code-named “Bochspwn” as a reference to the x86 emulator used (bochs: The Open Source IA-32 Emulation Project). In addition to discussing the instrumentation itself in both our SyScan 2013 presentation and the whitepaper we released shortly thereafter, we also went to some lengths trying to explain the different techniques which could be chained together in order to successfully and optimally exploit kernel race conditions, on the example of an extremely constrained win32k!SfnINOUTSTYLECHANGE (CVE-2013-1254) double fetch fixed by Microsoft in March 2013.
The talk has yielded a few technical discussions involving a lot of smart guys, getting us to reconsider several aspects of race condition exploitation on x86, and resulting in plenty of new ideas and improvements to the techniques we originally came up with. In particular, we would like to thank Halvar Flake (@halvarflake) and Solar Designer (@solardiz) for their extremely insightful thoughts on the subject. While we decided against releasing another 70 page long LaTeX paper to cover the new material, this blog post is to provide you with a thorough follow-up on efficiently winning memory access race conditions on IA-32 and AMD64 CPUs, including all lessons learned during the recent weeks.
Please note that the information contained in this post is mostly relevant to timing-bound kernel security issues with really small windows (in the order of several instructions) and vulnerabilities which require a significant amount of race wins to succeed, such as limited memory disclosure bugs. For exploitation of all other problems, the CPU subtleties discussed here are probably not quite useful, as they can be usually exploited without going into this level of detail.
All experimental data presented in this post has been obtained using a hardware platform equipped with an Intel Xeon W3690 @3.47GHz CPU (with Hyper-Threading disabled) and DDR3 RAM, unless stated otherwise.
1. Usefulness of attack time window expansion
In our original research, we showed how instructions with memory operands referencing user-supplied virtual addresses are a great vector for increasing the scope of an attack window by significantly delaying the completion of each such instruction. By employing different tricks (cache line and page boundaries, non-cacheability, TLB flushing), we managed to accomplish an approximate 2500x slowdown, starting at around a single cycle per a 32-bit memory fetch, and ending up at ~2700 cycles:
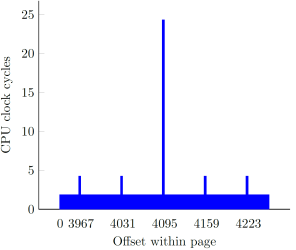
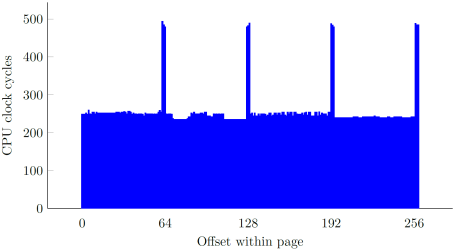
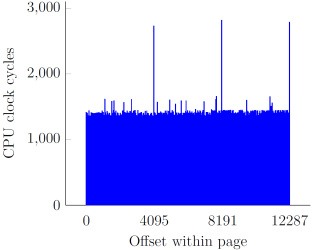
The overall effort of slowing certain CPU operations down to the maximum extent was based on the following implicit assumption: extending the time window indefinitely increases our chances to win the race. As it turns out, this is not always the case – while it is indeed beneficial to apply adequate techniques for extremely constrained vulnerabilities (such as the win32k.sys one), time window extension only works in the attacker’s favor up to a certain point, past which it can actually diminish the performance of an exploit. In order to better illustrate the phenomenon, we must consider the “arithmetic” and “binary” types of memory race conditions separately.
Arithmetic races
As a quick remainder, arithmetic races are double-fetch vulnerabilities which do not distinguish between the good and bad memory values, but rather use the fetched numbers directly during memory operations (e.g. as a memcpy size operand). In such cases, an attacker is not concerned about what values specifically are obtained from user-mode memory during the first and second fetch; they only need to make sure that both numbers differ from each other. An example of code affected by an arithmetic double-fetch is shown below:
PDWORD BufferSize = /* controlled user-mode address */;
PUCHAR BufferPtr = /* controlled user-mode address */;
PUCHAR LocalBuffer;
LocalBuffer = ExAllocatePool(PagedPool, *BufferSize);
if (LocalBuffer != NULL) {
RtlCopyMemory(LocalBuffer, BufferPtr, *BufferSize);
} else {
// bail out
}
Let’s assume the conditions are as follows: there are two CPUs – the first one continuously incrementing a 32-bit variable, and the other one triggering the vulnerable kernel code path. If the flip interval is constant (it normally is, except for situations involving thread preemptions on the flipping CPU), the following figure illustrates the exploitation process:
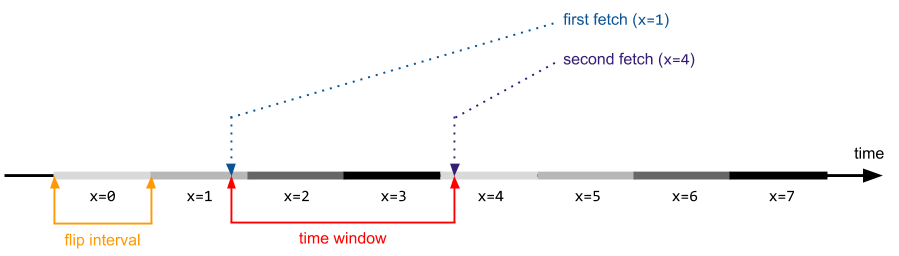
Now, if the original time window is smaller than the flip interval (which can also be thought of as a value duration), it is definitely reasonable to extend it, but only to the point where it is larger than the flip interval. Once the boundary is crossed, it becomes certain that the values obtained during the first and second fetches will be different. As experiments show, further increase of the window period can result in performance degradation, as it no longer increases the chance of a successful race win (it is already close to 100%), but instead reduces the total number of attempts per second.
The experiments depicted by the charts below were conducted in the following configuration: a 32-bit variable residing at a 4-aligned address and within cacheable memory region was being raced against. The flipping thread would continuously execute an INC DWORD PTR [VARIABLE] instruction in a tight loop, while the racing thread would execute the following function indefinitely, examining its return value after the completion of each call:
bool run_race(uint32_t *addr, uint32_t iter) {
// Load parameters to registers.
__asm("mov edx, %0" : "=m"(addr));
__asm("mov ecx, %0" : "=m"(iter));
// Perform the first fetch.
__asm("mov eax, [edx]");
// Loop `iter` times.
__asm("@@loop:");
__asm(" jecxz @@end");
__asm(" dec ecx");
__asm(" jmp @@loop");
// Perform second fetch and compare.
__asm("@@end:");
__asm("cmp eax, [edx]");
__asm("setnz al");
}
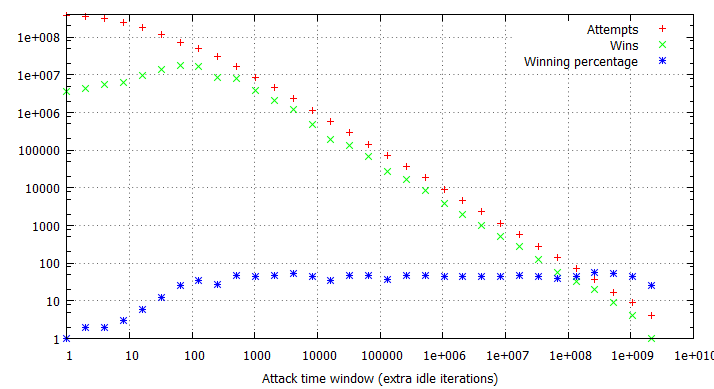
Pairs of the racing and flipping threads would be ran in iterations, one second each, with exponentially growing iter parameter, consequently blowing the attack time window out from virtually non-existent to dominating the thread time slice. Finally, the experiment was performed in three different configurations: with no additional overhead on invoking the run_race function and with 1,000 and 1,000,000 additional idle loop iterations. This way, we could determine how the constant time required to reach the vulnerable kernel code path affects the quantity of attempts and win rates per second. The results of the tests are illustrated in the charts below:
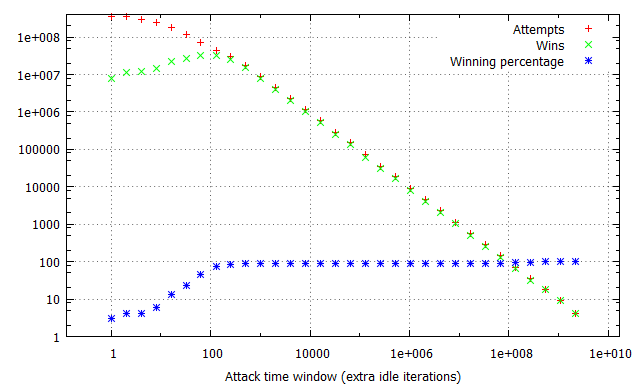
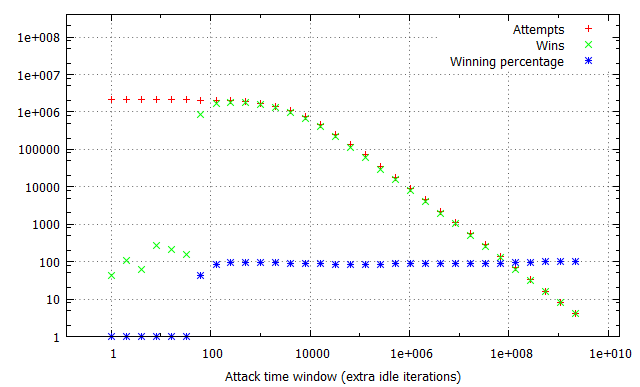
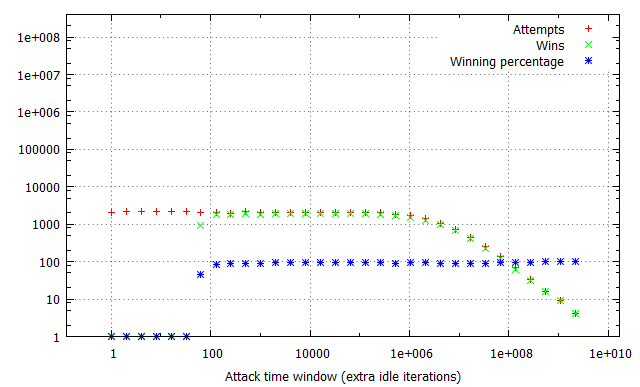
There are several long-standing conclusions which can be drawn from the above charts. First of all, the win ratio in relation to the time window takes an “S” shape characteristic to the logistic function – for time windows of limited length it is adequately small; at a certain point it begins to grow up to the point when it reaches a winning percentage of around 90-100%, where it settles and doesn’t significantly improve anymore. Visibly, the “critical point” for the attack window size (residing at circa 70 idle cycles in our example) depends solely on the flipping method and target hardware platforms (RAM latency etc.), and is not affected by other factors such as constant cost of a race attempt. Thus, the above benchmark can be successfully used to establish the average value duration in the raced memory and consequently figure out how much (if any) time window extension is required to reach a satisfying win rate.
Furthermore, you can observe how the attempts per second rate is influenced by the imposed attempt overhead and attack window size. For non-existent or negligible overhead, a growing time window completely dominates the overall attempt#/s rate – it is clearly visible that the number of run_race invocations drops by half between windows of 1 and 16 idle cycles during the first test. On the other hand, when each call of the vulnerable routine takes a noticeable amount of time (second and third tests), the initial part of the chart is flattened, as (relatively) small changes in the time window are outbalanced by the constant overhead. This explains why extending the time window for the win32k!SfnINOUTSTYLECHANGE vulnerability from ~250 to ~2500 cycles didn’t had much effect on the performance of our exploit – the threshold for achieving a close to 100% win rate was already reached at that point, and since the typical cost of invoking win32k!NtUserSetWindowLong is around 18 000 – 21 000 cycles long, the “optimization” didn’t visibly decrease the number of attempts per second either.
Overall, one should aim within a range of attack window sizes larger then the “attack threshold” value, but small enough to not become a dominant part in the overall vulnerable code path execution time. Considering that most vulnerable services (system calls, IOCTLs and so forth) should usually take several dozens of thousands of cycles, exceeding the optimal window size is not expected to be a frequent concern in an originally constrained scenario. On the other hand, if the vulnerability in question already offers an extensive window granting you a near-to-100% win ratio without employing any additional techniques, it is likely you should refrain from trying to extend the time window further (or thoroughly consider if doing so is of any benefit to your exploit).
Binary races
Contrary to arithmetic double fetches, the binary ones only allow for two different values to be stored within the repeatedly referenced variable. This is because the nature of the code which, containing the true time-of-check-to-time-of-use type of bug, performs explicit sanitization using one copy of the value and further uses another one to perform actual operations on memory. The attacker’s desire is to provoke a situation where the first fetch obtains a supposedly valid value (i.e. one passing the sanity checks), whereas the second retrieves a specially crafted number used for exploitation. One example of code affected by such problem is shown below:
__try {
ProbeForWrite(*UserPointer, sizeof(STRUCTURE), 1);
RtlCopyMemory(*UserPointer, LocalPointer, sizeof(STRUCTURE);
} except {
return GetExceptionCode();
}
Unlike arithmetic issues, we can no longer take it for granted that getting the time window to always cross the flip interval is enough to make sure that two consecutive reads will fetch different values. Due to the fact that there are only two possible variable states, we can frequently hit a condition where the code obtains the same value twice (even though it was changed in the meantime):
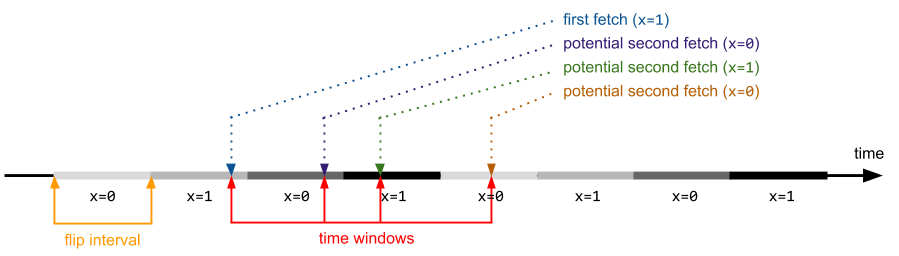
A direct consequence of the observation is that some lengths of time windows are more effective than others, e.g. if the window is twice the length of a flip interval, it should theoretically (if all of our simplified assumptions were true) never result in a win, while a flip interval and time window of equal lengths should always trigger the desired condition. In practice, things are obviously not that simple, but you can certainly notice that the winning percentages now span between 10% to 90% , depending on the particular time window size. Data presented below has been obtained using the exact same application as the previous section, only difference being the usage of a XOR instruction instead of INC. Please note that the specific results of binary race condition exploitation referred to in this post indicate the total number of situations where the variable value has changed within the time window, regardless of whether it was a bad → good or good → bad switch. In reality, you will always encounter roughly 50% of each situation, which should be taken into account when analyzing the charts below.
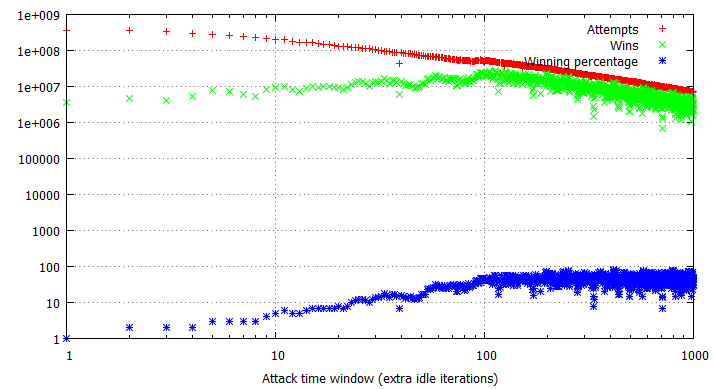
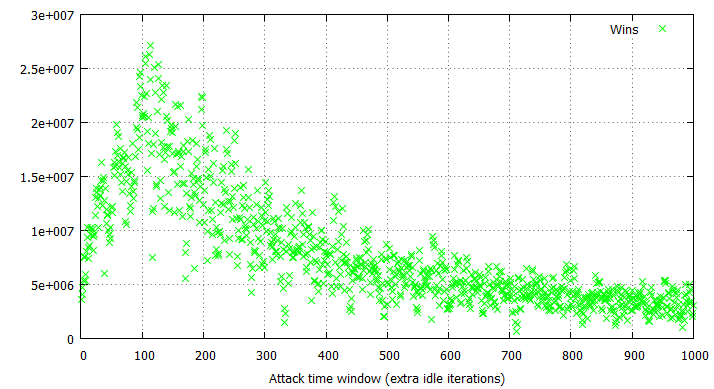
Despite the significant spread in win rates, it is still easy to locate the threshold for the most optimal time window length, being around 110-120 idle loop iterations in this particular case. Other than the dispersion, the attempt and win rates behave similarly to the arithmetical case (with the exception of more visible fluctuations), only being approximately half as effective:
In general, all rules discussed in the previous section apply with regards to binary double fetches; the one important difference to keep in mind is that certain specific window lengths tend to prove especially ineffective and should be avoided, if possible. These lengths are specific to the underlying hardware configuration; for example, a time window of 171 idle cycles would always yield win rates between 16 and 22% in our testing environment, even though many of the surrounding sizes would easily go up to 50%. Prior to conducting an attack against a binary double fetch, you should carefully examine if the available time window results in considerably poor exploit performance and should be adjusted.
2. Using two MOV instructions or an XCHG instruction for flipping bits
Alexander Peslyak has suggested to use two MOV instructions instead of whatever single instruction we proposed to use in the flipping thread, in both arithmetic and binary scenarios. The main advantage of the approach would be that MOV does not perform a “load” operation over the overwritten memory, it only does a “store” to write the desired data. Thanks to the optimization, it should be possible to reduce the flip interval, decreasing the required attack window size, which would consequently allow more attempts per second (and thus more wins).
Another idea shared by Alexander was to make use of the XCHG instruction as a replacement for all other previously mentioned variants of flipping combinations. As opposed to MOV, the potential motivation behind using XCHG would be to (in a sense) exploit the fact that the instruction is especially slow due to an implicit BUS LOCK associated with the instruction. As the Intel manuals state:
The operations on which the processor automatically follows the LOCK semantics are as follows: * When executing an XCHG instruction that references memory.
and elsewhere in the XCHG instruction documentation:
If a memory operand is referenced, the processor’s locking protocol is automatically implemented for the duration of the exchange operation, regardless of the presence or absence of the LOCK prefix or of the value of the IOPL.
Although the slow nature of the instruction contradicts with most of what we have learned about race conditions thus far, the memory lock assertion might actually come beneficial during the exploitation process due to how it interacts with other CPUs (and specifically the CPU executing the vulnerable routine). In order to finally determine which combination is most optimal (for binary and arithmetic cases), we tested the following six combinations using a 10,000-cycle overhead on the run_race function:
Arithmetic:
INC m32MOV m32, r32; INC r32XCHG m32, r32; INC r32
Binary:
-
XOR m32, r32MOV m32, r32; MOV m32, r32XCHG m32, r32
The results of the arithmetic instruction tests are as follows:
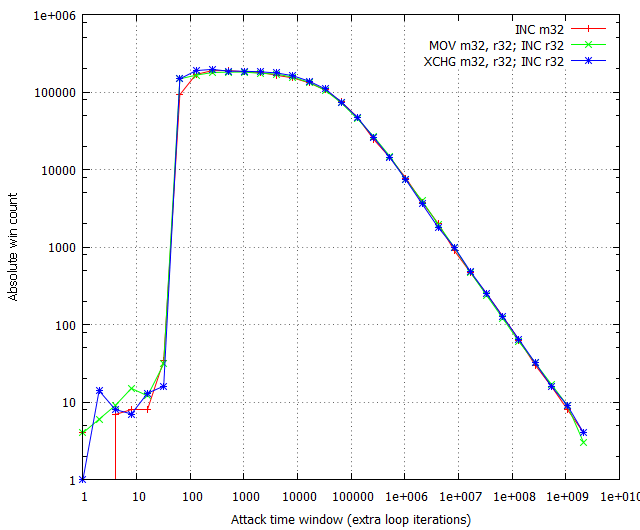
The chart shows that there is little to no difference in whichever memory modification instruction is used, provided the time window size is beyond the critical point. While it is true that the MOV instruction is generally faster than XOR and XCHG, the advantage is completely nullified by the fact that in any practical attack involving a time window of 100 or more cycles, the other instructions have the same winning percentage. Additionally, we indeed confirmed that the XCHG instruction does perform better than the other two exploitation-wise, but only for very small race invocation overhead; as Figure 9 shows, the advantage is not noticeable for an overhead of 10,000 cycles, which we believe to be a realistic simulation of real-life attack conditions. In the end, we believe there is no significant difference in using any of the three instruction combinations.
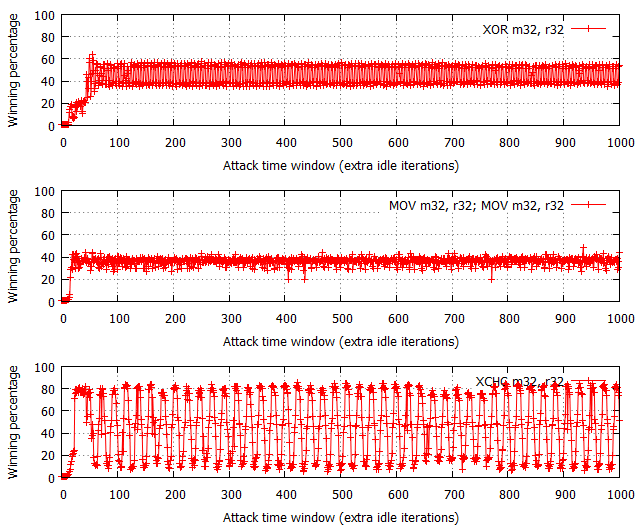
The performance of binary flipping instructions is much more interesting though, as shown in the following figures:
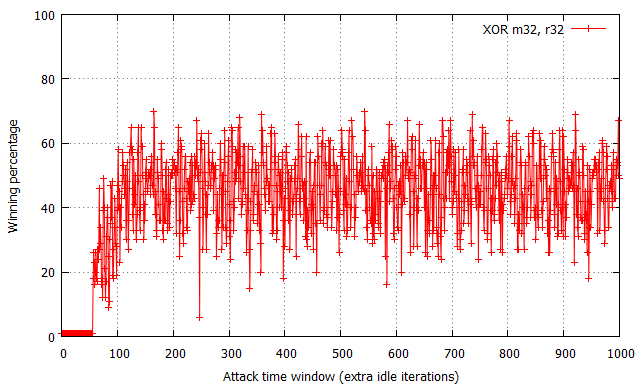
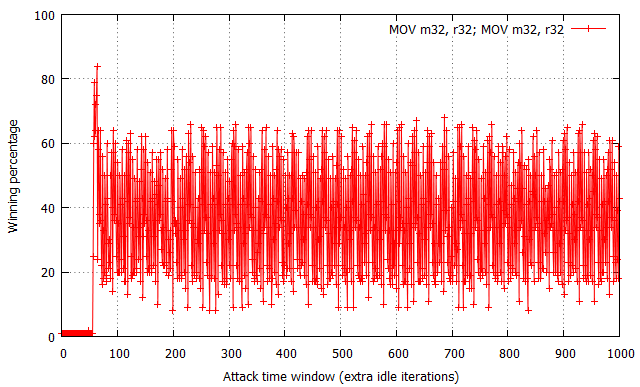
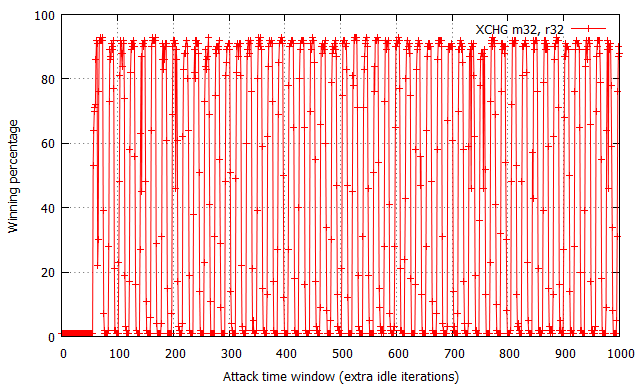
While not shown in the charts, the attempt#/s rates were measured to be comparable for all three tested configurations, fixed at around 200,000 attempts per second.
The XOR operation yields the most “non-deterministic” results – for each time window size past the ~60 cycle boundary, the winning percentages oscillate around 50% with occasional spikes and drops within the [30, 70]% range. There are no trivially observable trends in the chart, and thus performance is the most difficult to predict. Further on, the usage of two MOV flipping instructions has yielded significantly more regular results, with the winning percentage spanning from 15% to 65% effectiveness and a noticeable period of around 20-25 cycles. Most interestingly, the performance of the XCHG instruction (which asserts a bus lock) is extremely regular – it alternately achieves a win rate of 1% and ~90%, each series of equal percentages lasting for around 8-10 cycles.
While the average effectiveness of each of the three options is always around 50%, it is important to note that the win distribution relative to time window sizes makes each of them a distinct choice for exploitation. As the XOR results are typically closest to 50% regardless of the specific time window, it is likely the best choice for vulnerabilities where exploitation performance is not critical for the operation, or you wish the exploit code to remain simple and accomplish similar winning percentage on a number of machines regardless of their hardware and/or system configuration. In other words, it is the more generic solution, which is easy to use and guarantees relatively stable results. On the other hand, the MOV and XCHG solutions are much trickier to use – they (and specifically XCHG) offer the ability to achieve roughly twice the win rates of XOR, yet only if the time window length is correctly calibrated; a slight miss in aligning the window size and you might find yourself not winning any races at all. Therefore, it is probably the way to go where you really struggle for every single win and are able to control the double fetch timings to a large extent.
Given the interesting results we obtained on the Intel Xeon CPU, we decided to briefly test a handy Intel i5 chip (with Hyper-Threading used/unused) to see if the results and previously drawn conclusions would overlap. The following two charts show a comparison of the different operations’ performance with and without HT involved in the process.
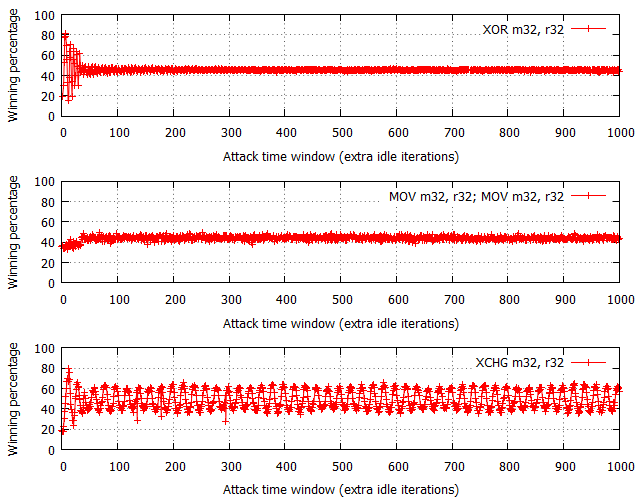
In case of the HT-enabled configuration, the results from i5 correspond to data obtained on a Xeon, only noticeable difference being that the winning percentage amplitudes are significantly smaller for all three instructions:
- XOR winning percentage ranges between 45-46% on i5 and 30-70% on Xeon.
- MOV+MOV winning percentage ranges between 42-48% on i5 and 15-65% on Xeon.
- XCHG winning percentage ranges between 35-65% on i5 and 1-93% on Xeon.
This is believed to be caused by the shorter access time to cache shared between the racing and flipping threads on different logical CPUs but same physical core.
Performance shown in Figure 14 is roughly similar to one illustrated in Figures 10-12 (Xeon) with the exception of XOR percentage now being of a much more regular shape and MOV+MOV performance circulating around 30-40% (the spread is smaller compared to XOR). In any case, it still holds true that XOR and MOV+MOV should be the best generic choices, but potentially better performance could be achieved with XCHG. Always remember to consider the purpose of the attack (maximum effectiveness or stealth) and target machine configuration before making a final call on the final flipping technique used.
Unfolding the loop
Another interesting idea we decided to explore (and which was also later suggested by Alexander) was unfolding the infinite loop responsible for changing the raced variable’s value. Originally, we assumed it would make most sense to employ the following simple piece of code:
@@: XOR m32, r32 JMP SHORT @@
where the XOR instruction could be replaced with any of the previously discussed combinations. However, “half” (instruction count-wise) of the flipping thread’s time is spent on an unconditional jump operation, whereas it could be potentially used to perform more data flips in that time. In order to achieve this, we could execute more than one flipping operation in each pass of the loop, thus reducing the share of the JMP instruction in the overall instruction execution stream.
We have already learned that further minimization of the value duration does not have direct positive effect on the exploitability of race conditions when the time window is larger than a few cycles. On the other hand, adding extra instructions to the loop could have some negative consequences: spamming the physical memory bus to the point where it causes system-wide memory access delays, consequently slowing down the racing thread. Despite our initial expectations regarding the concept, we decided to give it a try as an interesting exercise.
In the test, we used a configuration of a 10,000-cycle overhead for run_race, a time window of 200 cycles and INC / XOR instructions for the flipping. An overview of the results is below:
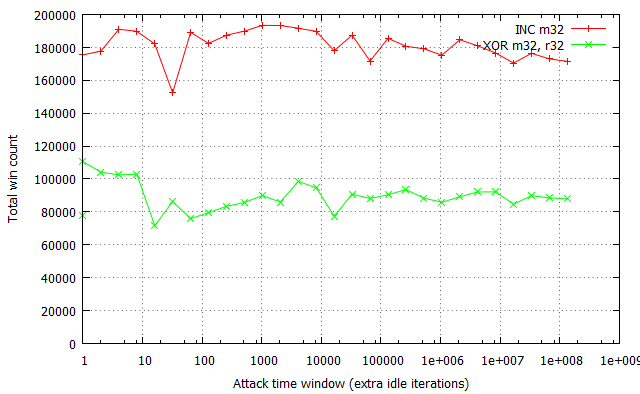
This and several other experiments we have carried out show that there is no visible correlation in the win rates per second and number of flipping instructions in the unfolded loop. The fluctuations in the chart above are typical for the flipping instructions used and not related to the degree of loop unfolding. Since it is always possible to extend the time window beyond the usual flip interval by employing some of the tricks discussed in SyScan, it is not required to artificially minimize the interval even further (using concepts such as this one), as it doesn’t have any effect on the final result.
Conclusions
In this post, we have tried to provide you with an explanation and some experimental data of the different improvement areas regarding kernel race condition exploitation. As previously noted, this information is only relevant to very specific vulnerabilities and attack scenarios; otherwise, it can also be considered as a set of interesting observations about the x86 architecture and its current implementations found in modern CPUs. Considering the humongous number of low-level, complex and undocumented memory access-related optimizations found in Intel and AMD units shipped nowadays, we find the output of any timing-related experiments involving interactions between separate CPUs extremely interesting (even though we often don’t fully understand the specific reasons behind the numbers).
Of course, you could think of a number of other potential exploit optimizations, such as replacing the flipping instruction’s operand from register to an immediate number or trying to get several binary flipping threads to get in sync to effectively shorten the flip interval, and so forth. We have tested a few of such approaches only to see that they didn’t have any effect on the overall performance, usually being just too subtle to maky any real difference. However, if you still have some good ideas on how the process could be improved, feel free to let us know. We hope we have managed to clear some of the more fundamental areas of memory access race condition exploitation; with some luck, this information will have a chance to prove useful one day in the future.
Cheers!
Thanks for the follow-up on the extremely long white paper (yes, I read all 65 pages).
Some constructive feedback: Please remember to label the graphs (e.g. the Y axis on almost every Figure). If there’s three different definitions, maybe label them in various colors. Based on context, I was able to figure it out eventually for all of them except Figure 15.
Also, I was confused near the beginning as how you were varying the number of instructions between the first and second access. I thought that would be determined by the specific vulnerability, and I was having trouble understanding how an attacker would be able to manipulate that. Eventually I figured out that they can’t (short of just going and finding another vuln), but it was just an example of how these techniques will work on different vulns.
The time lines were very helpful!
I’m very anxious to see the specifics on how you modified the emulator. Pages 16-21 of the paper conveyed the gist of it, but the details are still not entirely clear to me. I think when I see the code, that little light bulb will go on in my head.
Thanks for the feedback, Adam. I updated the charts I figured would actually require the y-label.
The post refers to different time window lengths, which are related to the number of instructions, but are often also controlled by the attacker. A piece of code which makes for the window between two fetches can take different numbers of cycles, depending on whether it contains references to user-mode memory (which ring-3 code can slow down, as shown in our white-paper), contains variable-iteration loops etc. That’s why we refer to window sizes here – we have tried to establish how useful it is to extend the time window with available techniques, and at which point it doesn’t make sense anymore.
You’ll get the instrumentation source code fairly soon, Black Hat is only a month away now. :)
One thing I don’t see: what is the solution/fix/prevention? Can you show code examples of how to prevent this bug?