
 During the past few weeks, I travelled around the world to give talks at several great security conferences, such as Ruxcon (Melbourne, Australia), PacSec (Tokyo, Japan), Black Hat Europe (London, UK) and finally Security PWNing Conference (Warsaw, Poland). At a majority of the events, I presented the results of my Windows Metafile security research, which took place earlier this year and yielded vulnerabilities in GDI (exploitable e.g. in Internet Explorer), GDI+ (e.g. Microsoft Office), ATMFD.DLL (Windows local privilege escalation) and the Virtual Printers mechanism in VMware Workstation. As part of the talks, I explained what GDI and metafiles really are, the process I followed while hunting for and identifying the vulnerabilities, and the exploitation paths for some of them. Finally, I discussed my approach to fuzzing a user-mode Windows DLL module on Linux machines (cross-platform), on the example of a 3rd party JPEG2000 decoder used in VMware products. Since my allocated time slots at both Ruxcon and PacSec were too short to cover the entirety of the material, I talked about the ATMFD.DLL vulnerabilities exclusively at Ruxcon, and about GDI+ only at PacSec. A complete list of the EMF bugs that were mentioned in the presentations can be found in the Google Project Zero tracker.
During the past few weeks, I travelled around the world to give talks at several great security conferences, such as Ruxcon (Melbourne, Australia), PacSec (Tokyo, Japan), Black Hat Europe (London, UK) and finally Security PWNing Conference (Warsaw, Poland). At a majority of the events, I presented the results of my Windows Metafile security research, which took place earlier this year and yielded vulnerabilities in GDI (exploitable e.g. in Internet Explorer), GDI+ (e.g. Microsoft Office), ATMFD.DLL (Windows local privilege escalation) and the Virtual Printers mechanism in VMware Workstation. As part of the talks, I explained what GDI and metafiles really are, the process I followed while hunting for and identifying the vulnerabilities, and the exploitation paths for some of them. Finally, I discussed my approach to fuzzing a user-mode Windows DLL module on Linux machines (cross-platform), on the example of a 3rd party JPEG2000 decoder used in VMware products. Since my allocated time slots at both Ruxcon and PacSec were too short to cover the entirety of the material, I talked about the ATMFD.DLL vulnerabilities exclusively at Ruxcon, and about GDI+ only at PacSec. A complete list of the EMF bugs that were mentioned in the presentations can be found in the Google Project Zero tracker.
 The second talk (presented at BH) focused purely on fuzzing and the various thoughts, techniques and results I arrived at after actively using this approach to uncover software security flaws for more than 5 years, both as part of and outside of work. The topics included gathering initial corpora of input files, extracting code coverage information from running programs, using this information to “distill” and manage live corpora (using a parallelized algorithm), interacting with our target application on various levels, and effectively mutating the input data to accomplish the best results. The presentation was then concluded with a brief analysis of my recent Windows kernel font fuzzing initiative, which has resulted in the discovery of 18 issues so far.
The second talk (presented at BH) focused purely on fuzzing and the various thoughts, techniques and results I arrived at after actively using this approach to uncover software security flaws for more than 5 years, both as part of and outside of work. The topics included gathering initial corpora of input files, extracting code coverage information from running programs, using this information to “distill” and manage live corpora (using a parallelized algorithm), interacting with our target application on various levels, and effectively mutating the input data to accomplish the best results. The presentation was then concluded with a brief analysis of my recent Windows kernel font fuzzing initiative, which has resulted in the discovery of 18 issues so far.
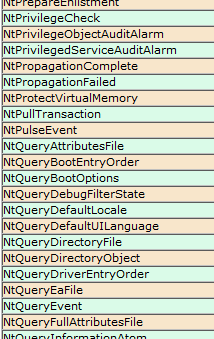 Those of you interested in the Windows kernel-mode internals are probably familiar with the syscall tables I maintain on my blog: the 32-bit and 64-bit listings of Windows system calls with their respective IDs in all major versions of the OS, available here (and are also linked to in the menu):
Those of you interested in the Windows kernel-mode internals are probably familiar with the syscall tables I maintain on my blog: the 32-bit and 64-bit listings of Windows system calls with their respective IDs in all major versions of the OS, available here (and are also linked to in the menu): During the weekend of May 21-23 (directly after the
During the weekend of May 21-23 (directly after the  This blog has experienced a long time of inactivity, as I’ve recently used it only to publish slides from conferences I presented at, with many months-long breaks in between. I am planning to change things up and start posting again in the upcoming weeks, starting with this blog post, which I originally wrote in early 2014. I haven’t posted it back then, as the bug in the FreeType project discussed here motivated me to look at other implementations of PostScript fonts and CharStrings specifically, which eventually resulted in an extensive research, dozens of bugs fixed by Microsoft, Adobe and Oracle, five long blog posts on the Google Project Zero blog (see the
This blog has experienced a long time of inactivity, as I’ve recently used it only to publish slides from conferences I presented at, with many months-long breaks in between. I am planning to change things up and start posting again in the upcoming weeks, starting with this blog post, which I originally wrote in early 2014. I haven’t posted it back then, as the bug in the FreeType project discussed here motivated me to look at other implementations of PostScript fonts and CharStrings specifically, which eventually resulted in an extensive research, dozens of bugs fixed by Microsoft, Adobe and Oracle, five long blog posts on the Google Project Zero blog (see the